Dashboard Overview
Comprehensive analysis of Massachusetts building inventory from NSI-Enhanced USA Structures Dataset
About This Dashboard
This interactive dashboard analyzes building data from the NSI-Enhanced USA Structures Dataset for Massachusetts. The analysis includes clustering patterns, temporal distributions, material characteristics, and soil properties of buildings across different time periods. All visualizations use color-blind friendly palettes and are fully interactive. Developed by Lang Shao (Fall 2025) and Tanvi Agarwal (Spring 2026) under the supervision of Prof. Demi Fang of the Structural Futures Lab. Data visualizations may not be suitable for distribution at this time and should include attribution. If you have any questions, please contact us.
MA Building Hierarchical Distribution
Multi-level breakdown: Occupancy → Area → Height → Year → Drainage
Construction Year → Occupancy → Material → Foundation → Soil
Base: Year → Occupancy. Toggle columns to the right.
Occupancy Class Hierarchy
Breakdown of Occupancy Classes (OCC_CLS) into Primary Occupancy types (PRIM_OCC).
OCC_CLS → NSI occtype matches
Each link sums the number of NSI points in polygons whose OCC_CLS equals the left-hand class. Counts are pooled per class (RES pool, COM pool, ...); points in other classes do not affect this pool.
Notes on NSI Damage Categories vs. Our Sankey Labels
The NSI technical documentation states that certain occtypes are folded into broader ‘damage categories’ : AGR and REL are counted under Commercial, while GOV and EDU are counted under Public. In this Sankey, we intentionally retain the original occtype labels and do not re-bucket them into those damage-category umbrellas (e.g., REL is not folded into Commercial).
Occupancy Homogeneity Score (MIX_SC) Distribution
Distribution of buildings based on the homogeneity of NSI point types within their footprint.
MIX_SC Categories Explained
Same Type Only (NaN in data): All NSI points inside the building polygon
are of the same primary type as the building itself.
1 Conflict Type (MIX_SC1): No NSI points of the same type as the building,
and all conflicting points are of a single different type.
Same & Different Types (MIX_SC2): The building contains NSI points of its
own type plus one or more conflicting types.
>1 Conflict Types (MIX_SC3): The building contains no NSI points of the
same type as the building, and has two or more different conflicting types.
Data Pipelines & Processing Pipeline
Understanding the data sources, predictions, cleaning, and distribution
Data Pipeline Overview
This section visualizes the journey of forging our powerful, multi-layered dataset from three distinct sources. We began with the USA Structures building inventory(MA only*) as our foundational layer. This base was then systematically enriched, first by incorporating structural characteristics('Year Built', 'Foundation Type', etc.) from the National Structure Inventory(NSI), and second, by adding crucial geotechnical context from the Web Soil Survey. The following diagrams visualize these complex joins, data cleaning procedures, and the final composition of the dataset...
NSI-Enhanced USA Structures Dataset Composition
Click on any data source to explore its contributed columns
Stage 1: Spatial Join to Create NSI Enhanced Version
USA Structures (Base)
2,091,488 Records
38 Columns
NSI Data Points
2,095,529 Records
15 Columns Added
Operation: Advanced Multi-Stage Spatial Join
An enhanced, multi-stage process was implemented to accurately enrich building footprints with NSI point data. This updated methodology features flexible handling of mixed-use properties, a precise nearest-neighbor buffer match, and systematic occupancy conflict detection to ensure data quality.
- Strategy 1: Intelligent Single-Family Matching
- For buildings classified as 'Single Family', the process now
flexibly considers both residential (
RES) and commercial (COM) NSI points inside. This accommodates mixed-use scenarios like in-home businesses. - If one point is found, a direct one-to-one match is made.
- If multiple points are found, their attributes are aggregated to create a composite profile, replacing the previous centroid-based selection. This robustly handles properties with multiple distinct units (e.g., a house with a separate commercial unit).
- For buildings classified as 'Single Family', the process now
flexibly considers both residential (
- Strategy 2: Standard Aggregation for Other Buildings
- For all other building types (multi-family, commercial, etc.), all NSI points falling within the footprint are used.
- Their attributes are aggregated to create a
comprehensive profile for the building:
- Value & Area (`structure_value`, `nsi_sqft`): Summed to get a total.
- Stories (`nsi_num_story`): The maximum value is taken.
- Characteristics (`year_built`, `material_type`): The statistical mode (most frequent value) is used.
- Strategy 3: Nearest Neighbor Buffer Match
- For NSI points that remain unmatched, this strategy finds the single nearest building polygon within a 5-meter radius.
- This ensures each point is uniquely assigned to its closest building, correcting for minor spatial inaccuracies. A single building can "absorb" multiple nearby points via this method.
- A configurable option also allows buildings already matched in earlier stages to absorb additional nearby points, capturing features like adjacent garages or utility structures.
- Extra Feature: Systematic Occupancy Conflict Detection
- Throughout the process, the script will actively compare the land use category of the NSI point (e.g., 'Commercial') against the category of the building polygon it falls into (e.g., 'Residential').
Stage Details & Unmatched Points(Click for detail)
Result: NSI Enhanced Structures v1
2,091,488 Records
53 Columns (38 Base + 15 from NSI)
A Left Join was performed, so all original buildings were retained. Unmatched buildings(405,037 in total) have NaN values for NSI columns(year_built, foundation_type, etc.).Stage 1.5: 'Unclassified' buildings from USA Structures were re-defined using NSI point data
How we re-label “Unclassified” using OCC_DICT
- Vote by counts in
OCC_DICT(e.g.,RES: 0, COM: 8, IND: 1, GOV: 0, EDU: 0 ...→ Commercial). - REL is counted as Assembly according to USA Structure PRIM_OCC column
(e.g.,
RES: 1, IND: 1, REL: 2→ Assembly). - If all
RES/COM/IND/GOV/EDU/AGR/RELare 0 → keep Unclassified. - If there is a tie in the vote (e.g.,
RES: 1, COM: 1), the building will remain Unclassified.
This relabeling occurs in the data cleaning step before any downstream
charts/tables,
so all occupancy analyses reflect the updated OCC_CLS.
Unclassified Reclassification Summary
How many Unclassified records were re-labeled into each class
Tie-Breaker Situations (Kept as Unclassified) - Click to expand
Stage 2: Building the Enhanced Soil Layer & Final Join
NSI-Enhanced USA Structures Dataset v1
2,091,488 Records (Polygons)
53 Columns
Input: GPKG (Preserves footprints)Web Soil Survey (WSS) Data
Sources: gsmsoilmu_a_ma.shp
Tables: comp.txt, chorizon.txt
12 Columns
Operation: Soil Enrichment & Area-Weighted Spatial Join
- Part A: Preparing the Enhanced Soil Layer
- 1. Component Filtering: Reads
comp.txtand selects only the single Dominant Component (highest percentage) for each Map Unit. - 2. Horizon Filtering: Reads
chorizon.txtand selects only Topsoil properties (depth < 10cm) to capture engineering characteristics relevant to foundations. - 3. Merge: Attributes are merged onto the Soil Shapefile to create a single, simplified soil layer.
- 1. Component Filtering: Reads
- Part B: Spatial Intersection (EPSG:26986)
- Data is projected to Mass State Plane (Meters) for accurate area measurement.
- A Polygon-on-Polygon intersection
(
predicate='intersects') is performed between buildings and soil layers.
- Part C: Area-Weighted Conflict Resolution
- Problem: Some buildings straddle the boundary between two or more soil map units.
- Solution: The script calculates the exact Overlap Area for every match. If a building touches multiple soil units, it is assigned to the one with the largest intersection area.
Result: NSI-Enhanced USA Structures Dataset v2
2,091,488 Records
65 Total Columns (53 + 12 from Soil)
Preserved Geometry: Polygons
Cleanup: IDs renamed tosoil_mukey/soil_cokey.
Buildings outside soil map coverage are labeled as "Unmatched" (retained via
Left Join).
Stage 2.5: CLF-Based Foundation Classification
NSI-Enhanced USA Structures Dataset v2
Input: GPKG (Polygons)
Target Column: foundation_type
65 Columns
CLF Categorization
Carbon Leadership Forum
Target Column: str_fdn_type
Operation: Dictionary Mapping & Type Cleaning
Mapping specific NSI foundation codes to broader str_fdn_type for standardized Carbon Analysis.
Result: NSI-Enhanced USA Structures Dataset v2.5
2,091,488 Records (Polygons Preserved)
+1 Column: general_fnd_type
66 Columns
Data Cleaning: All object columns converted to String to ensure GPKG stability and prevent "Error adding field" issues.Stage 3: Enriching with Demolition Permit Data
NSI-Enhanced USA Structures Dataset v2.5
Input: GPKG (Polygons)
66 Columns
Includesgeneral_fnd_type
Boston Approved Permit Dataset
Source: tmpbtz4x7bc.csv
Filter: EXTDEM, INTDEM, RAZE
3 Key Columns
Operation: Spatial Join (Polygons Preserved)
- 1. Priority-Based Deduplication: Filters permits and
selects the "best" record per address.
Priority Rule: Closed/Completed > Open > Most Recent Date. - 2. CRS Alignment (EPSG:2249): Both datasets are projected to MA State Plane (Meters) for precise distance calculation.
- 3. Nearest Neighbor Join (5m Radius): Uses
sjoin_nearestto find the single closest permit within 5 meters (from polygon edge).Matching Statistics (Total: 5,018):
● Exact Matches (In Polygon): 4,922 (98.1%)
● Buffer Matches (<5m): 96 (1.9%) - 4. Non-Destructive Merge: New attributes (`DEMOLITION_TYPE`, `DATE`, `STATUS`) are joined back using Index Alignment. This guarantees zero data loss and perfectly preserves original Polygon geometry.
Result: NSI-Enhanced USA Structures Dataset v3
2,091,488 Records
69 Total Columns (66 + 3 from Permits)
Geometry: MultiPolygon (Unchanged)
Validation: Original row count (2,091,488) perfectly preserved.Final Format: GPKG (Layer:
structures_demolition)
Stage 4: MassGIS Parcel Integration & Temporal Fusion Strategy
NSI-Enhanced USA Structures Dataset v3
Input: GPKG (Polygons)
2,091,488 Records
68 Columns
Contains original NSI Year DataMassGIS Parcels L3 Data
Source: Parquet (Chunked)
Unique Parcels: 2,623,246
1 Column
Processed via Dask LocalClusterOperation: High-Performance Spatial Join & Logic-Based Fusion
- 1. Centroid-Based Spatial Indexing: To optimize performance and accuracy, building geometries were converted to Centroids before performing a `within` spatial join against the MassGIS Parcel polygons.
- 2. Temporal Conflict Resolution (Latest Year Heuristic):
Handling parcels with multiple build years:- When a single building matched multiple parcel records (potential duplicates or subdivisions), the system prioritized the most recent construction year.
- Method: Data was sorted by
[BUILD_ID, YEAR_BUILT]in[Ascending, Descending]order, retaining only the top record.
- 3. Data Cleaning:
Outliers were removed by filtering
massgis_yr_builtto the valid range of 1630 - 2025. (1,709 invalid values detected and removed). - 4. Source Prioritization Strategy:
The decision logic for merging MassGIS and NSI year data is illustrated below:
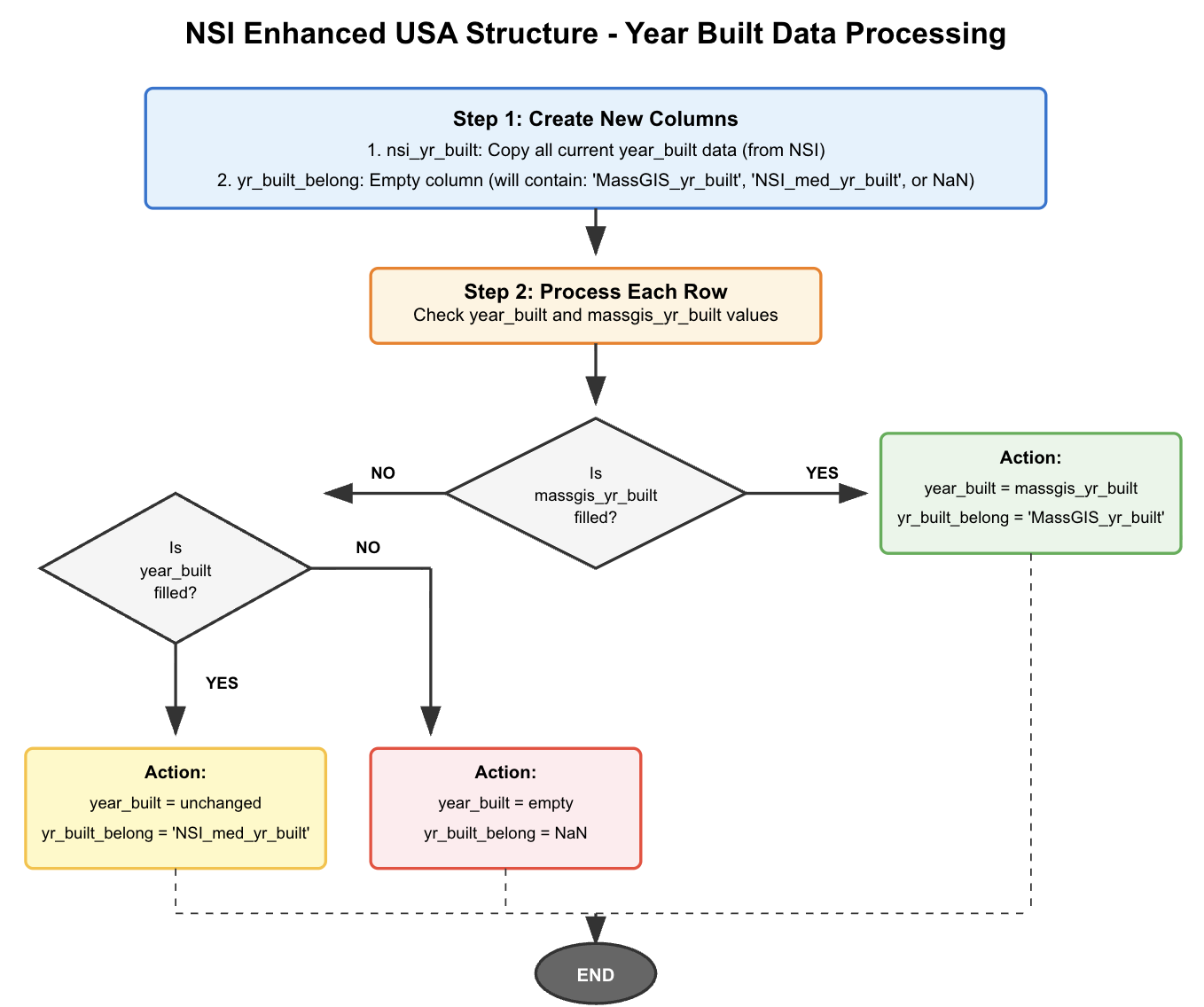
Data Fusion Statistics
Result: Final Integrated Dataset
2,091,488 Records (Polygons Preserved)
+3 Columns: massgis_yr_built, nsi_yr_built,
yr_built_belong
72 Columns Total
Output: ma_structures_FINAL_with_YR_SOURCE.gpkgData Sources vs. Final Result
Compare the original data sources (NSI vs MassGIS) or view the final cleaned distribution.
Geopackage data to Json data - Cleaning Process
How .gpkg data is filtered, cleaned and preprocessed to couple .json files
NSI Methodology Explained
The National Structural Inventory (NSI) sources key building attributes—such as year built and construction material—primarily from the commercial data provider Lightbox. When gaps or missing values occur in the Lightbox data, the NSI applies a logical random imputation methodology based on HAZUS tables to fill in those gaps. This process helps ensure the dataset’s overall completeness and quality. The diagram below shows the fill rate of attributes obtained directly from Lightbox. For any missing data, the NSI may have used HAZUS tables as substitutes.
NSI Data Sources & Predictions
How building material and foundation type data are obtained
Data Source Information
Lightbox provides 2,542,265 total MA building data records. Building material data is available for 1,208,023 records (47.52% coverage), and foundation type data for 54,497 records (2.14% coverage). Missing values are predicted using HAZUS methodology.
Removed Data Analysis
Explore buildings removed during data cleaning, categorized by missing features, geography, size, and year.
Why This Matters
This section evaluates whether data removal introduces bias — such as removing buildings disproportionately from certain cities, time periods, sizes, or materials.
Year Analysis
City Analysis
Size Distribution
Occupancy Analysis
Material & Foundation Distribution
Material & Foundation Removal Rates
Soil Properties and Risk Analysis
Comprehensive analysis of soil conditions and their impact on building infrastructure
Soil Data Categories
Drainage Classes: Well drained, Moderately well drained, Somewhat excessively
drained, Poorly drained, Very poorly drained, Excessively drained
Flooding Frequency: Low, Moderate, High
Engineering Properties:
<= 0.17 Favorable,> 0.17 and <= 0.24 Fair,> 0.24 and <= 0.32 Poor,> 0.32 Very poor
Soil Component: Various soil types identified by compname field
Risk Assessment Methodology
High-risk buildings are identified based on poor drainage conditions (Poorly drained or Very poorly drained) and/or frequent flooding risk (Occasional or Frequent). These conditions can impact foundation stability, basement flooding potential, and overall structural integrity over time. Buildings in high-risk zones may require additional maintenance and waterproofing measures.
Clustering Analysis
K-means clustering results based on building area, year built, and occupancy class (using a random sample for visualization)
Geographic Distribution of Clusters
Visualizing how the K-means clusters identified above are distributed spatially.
Temporal Distribution (1630 - 2025)
Building construction patterns over four centuries
Multi-Dimensional Occupancy Clustering Analysis
Advanced clustering analysis with dynamic feature selection for true multi-dimensional clustering
Dynamic Clustering Features
Base Dimensions (4D): Year Built, Footprint Area (SQMETERS), Height
(HEIGHT_USED — measured HEIGHT when available, otherwise PRED_HEIGHT), Occupancy Class
+ Material Type (5D): Adds material type as a clustering dimension
+ Foundation Type (5D): Adds foundation type as a clustering dimension
+ Both (6D): Includes all dimensions for comprehensive clustering
Real-time Reclustering: Each toggle change triggers new clustering calculations
based on selected features
Building Materials & Foundation Analysis
Correlation between material types and foundation types - Click on any cell to see occupancy breakdown
Material & Foundation Type Codes
Material Types: M = Masonry, W = Wood, H = Manufactured, S = Steel, C =
Concrete
Foundation Types: C = Crawl Space, B = Basement, S = Slab, P = Pier, I = Pile,
F = Fill, W = Solid Wall
👉 Click on any cell in either heatmap to see the occupancy
class distribution for that combination
Material Usage Trends Over Time
Normalized percentage of material types for new construction in each decade.
Boston's Historic Shoreline and Filled Land
Visualizing buildings constructed on land reclaimed since 1630.
The Filling of Boston
The map of Boston has changed dramatically since its founding in 1630. Much of what is now considered central Boston was once tidal flats and marshes. Through extensive land reclamation projects over centuries, areas like Back Bay, the South End, and parts of Downtown were created from fill. This historic map shows the original 1630 shoreline, and the interactive map below displays modern buildings that now stand on this reclaimed land.
Historic Shoreline Map (c. 1630)
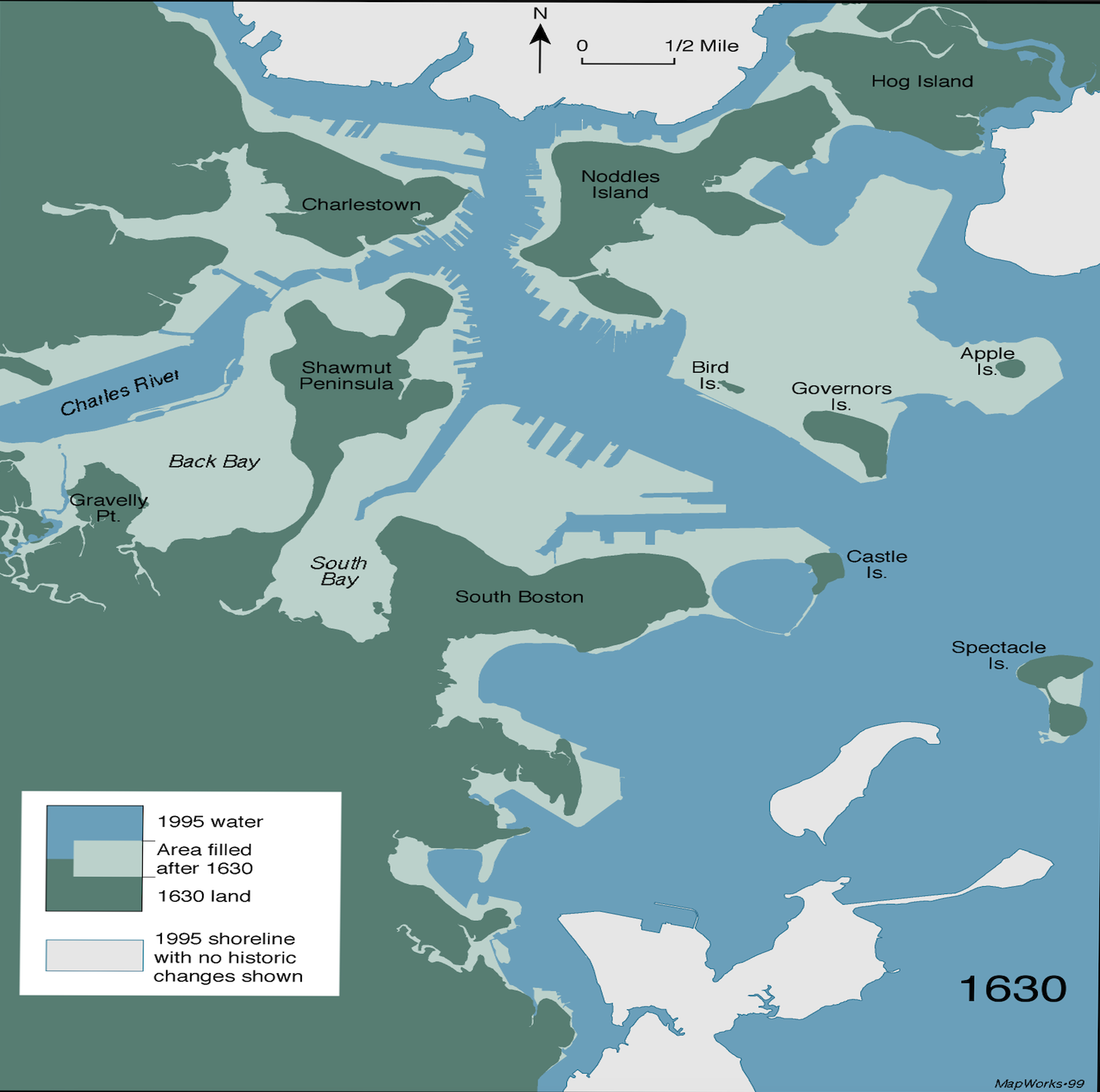
Buildings on Reclaimed Land
An interactive map of structures located on areas that were filled after 1630.
Boston Foundation Type Analysis by Building Height
Comprehensive analysis of foundation types on Original vs. Filled Land across height bins.
Methodology & Data Processing
CLF Foundation Type: CLF (Carbon Leadership Forum) is a non-profit organization that provides building embodied carbon data. The buildings_metadata.xlsx contains structural and foundation information for buildings across North America. Foundation types are grouped into CLF categories: Shallow foundation, Deep foundation < 50' (15m), Deep foundation > 50' (15m), and Other Foundation System.
Shoreline Detection: Buildings are classified using the 1630 historic shoreline.
Height Binning: Buildings are categorized into 5 bins based on height.
Section 1: Original Land vs Shoreline Land Comparison
Section 2: Height bin comparison within same land type
Section 3: Complete Data Overview (Click to Expand) ▶
Section 4: CLF Metadata Height vs Foundation Analysis
Data source: CLF buildings_metadata.xlsx (covers all of North America)
| CLF Height Bin | Our Height Bin |
|---|---|
| 0-7.5 m | 0-24 ft |
| 7.6-15 m | 24-72 ft |
| 15.1-22.5 m | 24-72 ft |
| 22.6-30 m | 72-147 ft |
| 31-45 m | 147+ ft |
| 46-60 m | 147+ ft |
| 61-90 m | 147+ ft |
| Over 90 m | 147+ ft |
Cost Analysis
Explore structural cost patterns across building size, occupancy, and materials
Cost Metrics Overview
This section analyzes building structural value (structure_value) and cost intensity relative to Gross Floor Area (GFA). Visualizations reveal how cost scales by occupancy and construction material.
Log-Log Regression: Structure Value ~ GFA
Cost Intensity by Occupancy Class
Cost Intensity by Material Type
Interactive Data Explorer
Explore the data with custom filters and advanced visualizations (*Data from 75,000 random sampled data from 1.7M cleaned dataset)
Tips for Interactive Explorer
• 3D Scatter: Rotate with mouse, zoom with scroll wheel
• Sunburst: Click segments to zoom in, click center to zoom out
• Parallel Coordinates: Drag axes to reorder, brush to filter
• All charts: Hover for details, double-click to reset view
CLF Data Analysis
Analysis of Carbon Leadership Forum dataset for Massachusett
CLF Data Preprocessing
This dataset originates from the New Construction MA Projects from the CLF building metadata, processed to be compatible with the NSI Enhanced USA Structure dataset. Key transformations include:
Occupancy Classification (OCC_CLS)
Detailed CLF building uses were mapped to NSI Enhanced USA Structure dataset categories.
This mapping is primarily based on the definitions from the USA Structure dataset's
PRIM_OCC column.
| CLF Building Use | Mapped NSI Category (OCC_CLS) |
|---|---|
| Multifamily (5 or more units) | Residential |
| Lodging | Residential |
| Office | Commercial |
| Mercantile | Commercial |
| Food Service | Commercial |
| Laboratory | Commercial |
| Healthcare | Commercial |
| Parking | Commercial |
| Public Order and Safety | Government |
| Warehouse and Storage | Industrial |
| Industrial | Industrial |
| Public Assembly | Assembly |
| Religious Worship | Assembly |
| Transportation Hub | Assembly |
| Education | Education |
| Other | Utility and Misc |
Material Type Encoding (material_type)
CLF structural systems were mapped to single-letter codes.
This mapping was inferred by combining several CLF columns:
str_prim_horiz_sys, str_prim_vert_sys, str_lat_sys,
and str_sec_vert_sys.
| CLF Structural System | Mapped Code (material_type) |
|---|---|
| Steel | S |
| Concrete | C |
| Steel/Concrete | S |
| Steel/Masonry | S |
| Wood: Mass Timber | W |
| Wood: Light-frame | W |
| Other | H |
| M = Masonry, W = Wood, H = Manufactured, S = Steel, C = Concrete (in NSI Enhanced USA Strucuture dataset) | |
Other Key Transformations
bldg_compl_yearwas mapped toyear_builtbldg_cfawas mapped toEst GFA sqmetersstr_fdn_typewas mapped togeneral_fnd_type- Height Standardization: Text descriptions (e.g., "10-12 m") were converted to numeric averages (e.g., 11 in the HEIGHT column, which is in meters).
- Data Cleaning: 2 Records with missing floor area data (Est GFA sqmeters) were removed.
- Finally 16 projects from CLF are analyzed
Scatter Plot CLF MA Data Explorer
Compare GFA, Total Mass, and GWP, colored by Occupancy Class.
CLF Heatmap Analysis
Correlation between foundation types and structural systems.
Mapped Material Type vs. Foundation Type
Original Structural System vs. Foundation Type
GFA Distribution: Main Dataset vs. CLF Dataset
Comparison of Est GFA (sqm) by Occupancy Class. Boxes represent the main dataset (from 75,000 random sampled data from 1.7M cleaned dataset); 'x' markers represent the CLF dataset.
Error Loading Data
Unable to load building data. Please ensure building_data.json is in the same directory.